浏览器的工作原理
2021年10月12日
25分钟阅读
2 次浏览
0 条评论
> 说明:本章内容为主要参考了bilibili Up主 objtube卢克儿的视频,视频链接为<https://www.bilibili.com/video/BV1x54y1B7RE?from=search&seid=2513294459098846528/>,讲得真的是很不错 1 浏览器是如何运转的 为什么我们要去了解浏览器的工作原理呢? 很简单,让你写出更好的代码和提供更好的用户体验。 ...
说明:本章内容为主要参考了bilibili Up主 objtube卢克儿的视频,视频链接为https://www.bilibili.com/video/BV1x54y1B7RE?from=search&seid=2513294459098846528/,讲得真的是很不错
1 浏览器是如何运转的
为什么我们要去了解浏览器的工作原理呢?
很简单,让你写出更好的代码和提供更好的用户体验。 浏览器对前端的工程师就像赛车对于一个赛车手一样,你需要对自己的战车足够的了解,才能跑得更快,弯道拐的更优雅。
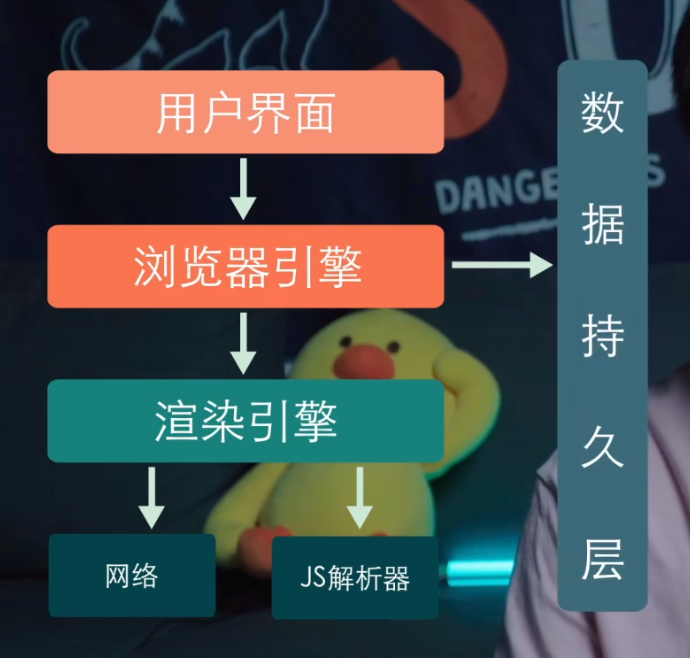
浏览器结构图
大致可以简单的分为用户界面、浏览器引擎、渲染引擎。
- 用户界面用于展示除标签页、窗口之外的其他用户界面内容
- 渲染引擎负责渲染用户请求的页面内容。
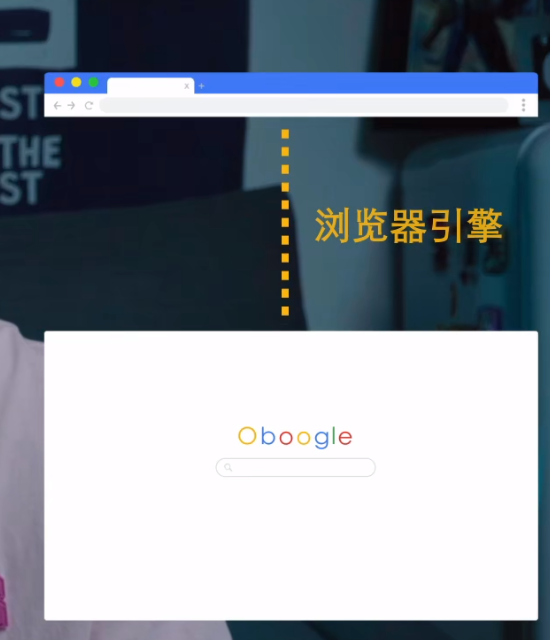
- 在用户界面和渲染引擎之间有个浏览器引擎,用于在用户界面和渲染引擎之间传递数据。
- 渲染器下面还有很多小的功能模块,比如负责网络请求的网络模块,用于解析和执行js的解析器,还有数据存储持久层,用于帮助浏览器存储各种数据,比如cookie等等。
渲染引擎可以说是一个浏览器的核心与灵魂。
我们往往会把渲染引擎称为浏览器的内核,不同浏览器使用的内核也不大一样
其中IE使用的是Trident,Firefox使用的是Gecko,Safari使用的是Webkit并将其开源,然后chorme使用的是基于Webkit改造优化的的Blink渲染引擎,也将其开源。Opera和Edge使用的是Blink。可以看到Webkit项目的开源对浏览器的发展做了多大的贡献。
浏览器是运行在操作系统上的一个应用程序。每个应用程序必须至少启动一个进程来执行其功能,每个程序往往需要运行很多任务,那进程就会创建一些线程来帮助他去执行这些小的任务。
进程是操作系统进行资源分配和调度的基本单元,可以申请和拥有计算机资源。 进程是程序的基本执行实体,线程是操作系统能够进行运算、调度的最小单位。一个进程可以并发多个线程,每条线程并行执行不同的任务。
简单来说:
当我们启动某个程序时,就会创建一个进程来执行任务代码,同时会为该进程分配内存空间,该应用程序的状态都保存在该内存空间里,当应用关闭时,该内存空间就会被回收。
进程可以启动更多的进程来执行任务。
由于每个进程分配的内存空间是独立的,如果两个进程间需要传递某些数据,则需要通过进程间通信管道IPC来传递。
很多应用程序都是多进程的结构,这样是为了避免某一个进程卡死,而造成整个应用程序的崩溃。
你可以把笔记本电脑想象成一个应用程序,外接鼠标是该应用程序的一个进程,如果外接鼠标出了问题,并不会影响你继续使用笔记本电脑。
进程可以将任务分成更多细小的任务,然后通过创建多个线程,并行执行不同的任务,同一进程下的线程之间是可以直接通信、共享数据的。
浏览器也是一个多进程结构,但早期的浏览器并不是多进程的结构,而是一个单进程的结构。 一个进程中大概有页面线程负责页面渲染和展示等,js线程执行js代码,还有其他各种线程。单进程的结构引发了很多问题
一是不稳定,其中一个线程的卡死可能会导致整个进程出问题。
比如你打开多个标签页,其中一个标签卡死,可能会导致整个浏览器无法正常运行。
二是不安全。
浏览器之间是可以共享数据的,那js线程岂不是可以随意访问浏览器进程内的所有数据?
三是不流畅,一个进程需要负责太多事情,会导致运行效率的问题。
所以为了解决这一这些问题
现在采用了多进程浏览器结构,根据进程功能不同来拆解浏览器

-
其中浏览器进程负责控制chrome浏览器除标签页外的
用户界面,包括地址栏、书签、后退和前进按钮,以及负责与浏览器的其他进程协调工作。 -
网络进程负责发起、接受网络请求
-
gpu进程负责整个浏览器界面的渲染
-
插件进程负责控制网站使用的所有插件,例如flash。 这里的插件并不是指的chrome市场里安装的扩展
-
渲染器进程用来控制、显示tab标签内的所有内容。 浏览器在默认情况下会为每个标签页都创建一个进程,为什么这里会说有可能呢?
这和你启动chrome时选择的侵权模型有关。 在chromium的官方文档上说明了chrome一共有四种进程模型,分别是默认的process-per-site-instance。默认情况下,chromium为用户访问的网站的每个实例创建一个渲染器进程,这样可以确保来自不同站点的页面是独立呈现的,并且对同一站点的单独访问也是彼此隔离的。 简单来说就是访问不同站点和同一站点的不同页面都会创建新的进程。process-per-site模型表示同一站点使用同一进程,process-per-tab表示一个tab里的所有站点使用一个进程。single-process都会让浏览器引擎和渲染引擎共用一个进程。
显而易见,process-per-site-instance模型会创建更多的进程,占用更多的内存空间,但确实是最安全的。 每个tab以及tab内的每个站点都是相互隔离、互不影响的。 当其中一个标签页渲染器进程卡死,并不会影响其他标签。
当你在地址栏输入地址时,浏览器进程的UI线程会捕捉你的输入内容。 如果访问的是网址,在UI线程会启动一个网络线程来请求DNS进行域名解析,接着开始连接服务器获取数据。 如果你的输入不是网址,而是一串关键词,浏览器就知道你是要搜索,于是就会使用默认配置的搜索引擎来查询。
当网络线程获取到数据后,会通过SafeBrowsing来检查站点是否是恶意站点,如果是,则会展示个警告页面,告诉你这个站点有安全问题,浏览器会阻止你的访问。 当然你也可以强行继续访问。
SafeBrowsing是谷歌内部的一套站点安全系统,通过检测该站点的数据来判断是否安全。 比如通过查看该站点的ip是否在谷歌的黑名单之内。
当请求返回数据准备完毕并且安全校验通过时,网络线程会通知UI线程,我这儿准备好了,该你了。 然后UI线程会创建一个渲染器进程来渲染页面,浏览器进程通过IPC管道将数据传递给渲染器进程,正式进入渲染流程
渲染器进程接收到的数据也就是html,渲染器进程的核心任务就是把html,js,css与image等资源渲染成用户可以交互的web页面。
渲染器进程的主线程将HTML进行解析,构造DOM数据结构。 DOM也就是文档对象模型,是浏览器对页面在其内部的表示形式,是外部开发程序员可以通过js与之交互的数据结构和api。
html首先经过tokeniser标记化,通过词法分析,将输入的html内容解析成多个标记,根据识别后的标记进行DOM树构造。 在DOM树构造过程中会创建document对象,然后会对以document为根节点的DOM树不断进行修改,向其中添加各种元素。
html代码中往往会引入一些额外的资源,比如图片、css和js脚本等。
图片和css这些资源需要通过网络下载或者从缓存中直接加载,这些资源不会阻塞html的解析,因为它们不会影响DOM树的生成。
但当html解析过程中遇到script的标签,将停止html解析流程,转而去加载、解析并且执行js。
你可能就会问了,为什么不直接跳过js的加载和执行这一过程,等HTML解析完成后再加载、运行js呢?
这是因为浏览器并不知道js的执行是否会改变当前页面的html结构。 如果js代码里调用了document.write方法来修改html,那之前的HTML解析就没有任何意义了。 这也就是为什么我们一直说要把script标签要放在合适的位置,或者使用async或defer属性来异步加载执行 js,
在HTML解析完成后,我们就会获得一个DOM树,但我们还不知道DOM树每个节点应该长什么样子,那么主线程需要解析css并确定每个DOM点的计算样式,即使你没有提供自定义的css样式,浏览器 也会有自己默认的样式表,比如h2的字体要比h3的大,
要知道DOM结构和每个节点的样式,我们接下来需要知道每个节点应该放在页面上的哪个位置,也就是节点的坐标,以及该节点需要占用多大的区域。 这个阶段被称为layout布局。
主线程通过dom和计算好的样式来生成layout tree 。layout tree每个节点都记录了x、y坐标和边框尺寸。
这里需要注意的一点是,dom树和layout tree并不是一一对应的,设置了display.none 的节点不会出现在layout tree上。而在before伪类中添加了content值的元素,content里的内容会出现在layout tree上,不会出现在DOM树里。这是因为dom树是通过html解析获得,并不关心样式。
而layout tree是根据DOM和计算好的样式来生成。
layout tree的顺序和最后展示在屏幕上的节点是对应的。
现在我们已经知道了元素的大小、形状和位置,这还不够,我们还需要知道以什么样的顺序绘制这个节点。 举例来说,z-index这个属性会影响节点绘制的层级关系,如果我们按照DOM的层级结构来绘制页面,则会导致错误的渲染
所以为了保证在屏幕上展示正确的层级关系。主线程会遍历layout tree创建一个绘制记录表,该表记录了绘制的顺序,这个阶段被称为绘制。
现在知道了文档的绘制顺序,终于到了该把这些信息转化成像素点显示在屏幕上的时候了。 那这种行为被称为栅格化。chrome最早使用了一种很简单的方式,只栅格化用户可视区域的内容,当用户滚动页面时,再栅格化更多的内容来填充缺失的部分。 这种方式带来的问题显而易见,会导致展示延迟。
随着不断的优化、升级,现在的chrome使用了一种更为复杂的栅格化流程,叫做合成。
合成是一种将页面的各个部分分成多个图层,分别对其进行栅格化,并在合成器线程中单独进行合成页面的技术。
简单来说就是页面所有的元素按照某种规则进行分图层,并把图层都栅格化好了,然后只需要把可视区的内容组合成一帧展示给用户即可。
主线程遍历layout Tree生成layer tree,当layer tree生成完毕和绘制顺序确定后,主线程将这些信息传递给合成器线程。
合成器线程将每个图层栅格化,由于一层可能像页面的整个长度一样大,因此合成器线程将它们切分为许多图块,然后将每个图块发送给栅格线程,栅格线程栅格化每个图块,并将它们存储在gpu内存中。
当图块栅格化完成后,合成器线程将收集称为draw quads的图块信息,这些信息里记录了图块在内存中的位置和在页面的哪个位置绘制图块的信息。
根据这些信息,合成器线程生成了一个合成器帧,然后这个合成器帧通过IPC传送给浏览器进程
接着浏览器进程将合成器帧传送到gpu,然后gpu渲染展示到屏幕上,
当你的页面发生变化,比如你滚动了当前页面,都会生成一个新的合成器帧。新的帧, 再传给gpu,然后再次渲染到屏幕上。
总结:
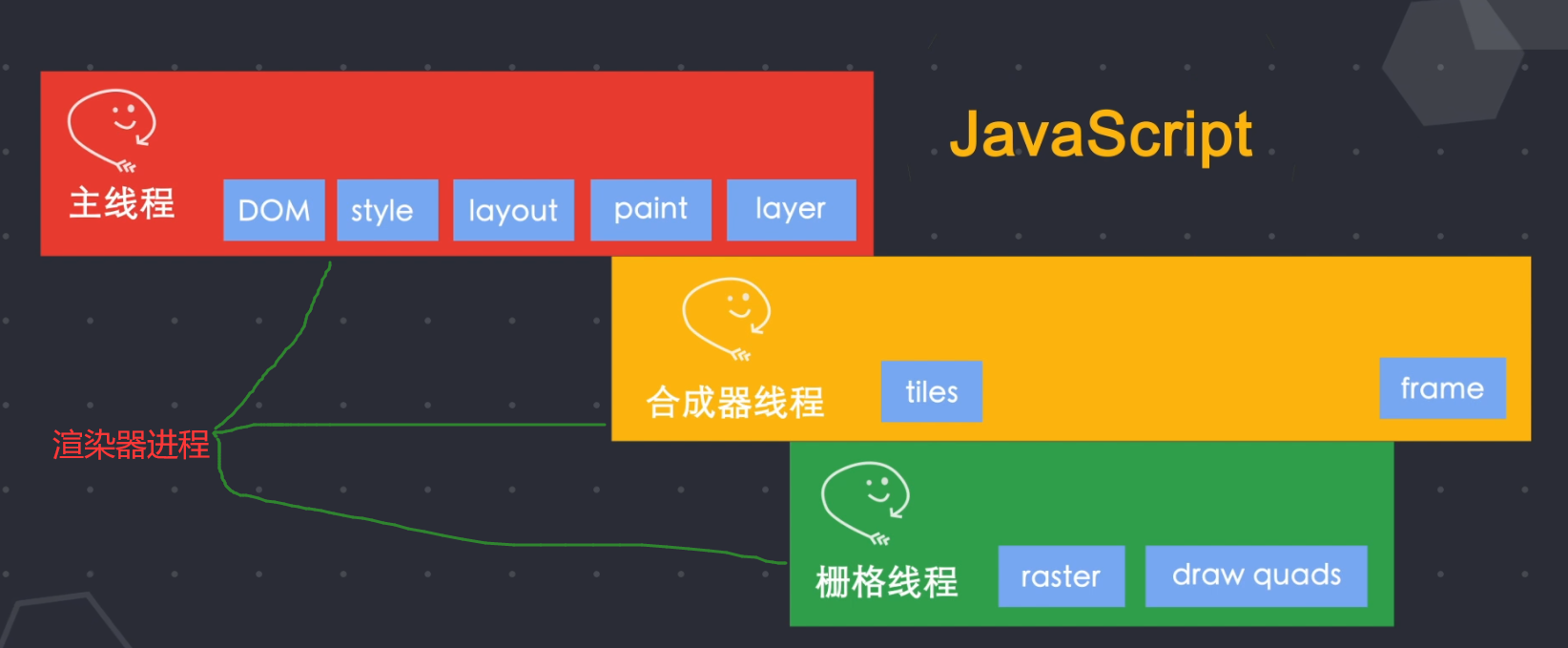
浏览器进程中的网络线程请求获取到html数据后,通过IPC管道将数据传给渲染器进程的主线程,主线程将html解析构造DOM树,然后进行样式计算,根据DOM树和生成好样式生成layout tree处理,通过遍历layout tree生成绘制顺序表,然后主线程将layout tree和绘制顺序信息一起传给合成器线程。 合成器线程按规则进行分图层,并把图层分为更小的图块儿,传给栅格线程进行栅格化。 栅格化完成后,合成器线程会获得栅格线程传过来的draw quads图块信息,根据这些信息,合成器线程合成了一个合成器帧,然后将该合成器帧将通过IPC传回给浏览器进程。 浏览器进程,再传到gpu进程进行渲染,最后就展示到你的屏幕上了。
当我们改变一个元素的尺寸、位置、属性时,会重新进行样式计算、布局、绘制以及后面的所有流程,这种行为我们称为重排。
当我们改变某个元素的颜色属性时,不会重新触发布局,但还是会触发样式计算和绘制,这个就是重绘。
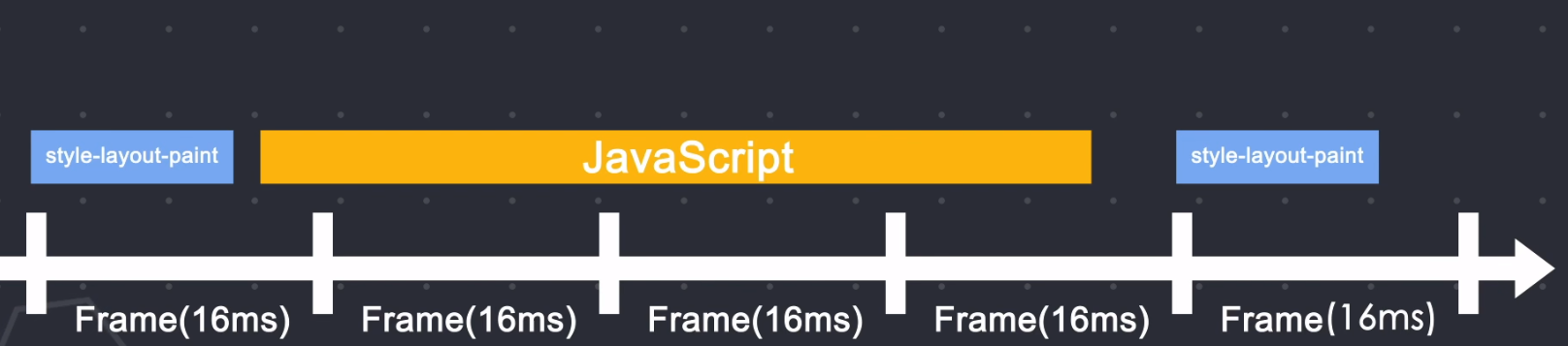
我们可以发现重排和重绘都会占用主线程,那还有另外一个东西也是运行在主线程。 对,那就是js。 既然他们都是在主线程运行,就会出现抢占执行时间的问题。
如果你写了一个不断导致重排、重绘的动画,浏览器则需要在每一帧都运行样式计算、布局和绘制的操作。 我们知道当页面以每秒六十帧的刷新率运行时,才不会让用户感觉到页面卡顿。 如果你在运行动画时还有大量的js任务需要执行,因为布局、绘制和js的执行都是在主线程运行的。 当在一帧的时间内布局和绘制结束后,还有剩余时间,js就会拿到主线程的使用权。 如果js执行时间过长,就会导致在下一帧开始时js没有及时归还主线程,导致下一帧动画没有按时渲染,就会出现页面动画的卡顿。
那有什么优化的手段吗? 有。
第一种就是可以通过requestAnimitionFrame这个api来帮助我们解决这个问题。requestAnimitionFrame这个方法会在每一帧被调用。 我们可以把js运行任务分成一些更小的任务块,在每一帧时间用完前暂停js的执行,归还主线程,这样的话在下一帧开始时,主线程就可以按时执行布局和绘制。
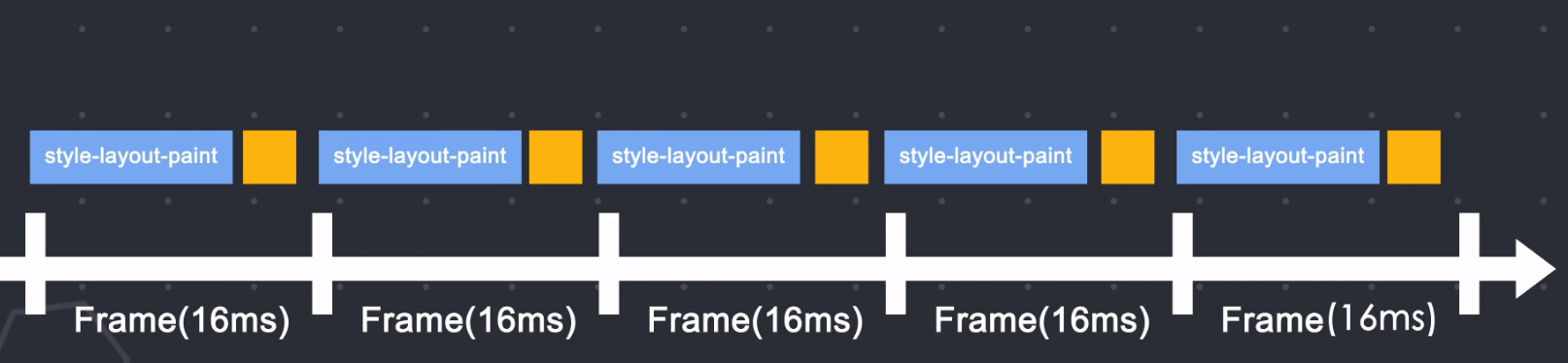
react最新的渲染引擎React fileber就是用到了这个api来做了很多优化。
还有第二个优化方法,通过刚才的流程图我们知道栅格化的整个流程是不占用主线程的,只在合成器线程和栅格线程中运行,这就意味着它无需和js抢夺主线程。
如果反复进行重绘和重排,可能会导致掉帧,这是因为有可能js执行阻塞了主线程。
而css中有个动画属性叫transform,通过该属性实现动画,不会经过布局和绘制,而是直接运行在合成器线程和栅格化线程中,所以不会受到主线程中js执行的影响。 更重要的是通过transform实现动画,由于不需要经过样式计算,布局、绘制等操作,所以节省了很多运算时间。
位置变化、宽高变化(旋转、3D等,那这些都是可以使用transform来代替的。
补充:
-
浏览器内核就是浏览器渲染进程,从接收下载文件后再到呈现整个页面的过程,由浏览器渲染进程负责。浏览器内核是多线程的,在内核控制下各线程相互配合以保持同步,一个浏览器通常由以下常驻线程组成:
GUI渲染线程- 定时触发器线程
- 事件触发线程
- 异步
http请求线程 JavaScript引擎线程
GUI渲染线程
GUI渲染线程负责渲染浏览器界面HTML元素,当界面需要重绘(Repaint)或由于某种操作引发回流(reflow)时,该线程就会执行。定时触发器线程
浏览器定时计数器并不是由
JavaScript引擎计数的, 因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确, 因此通过单独线程来计时并触发定时是更为合理的方案。事件触发线程
当一个事件被触发时该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理。这些事件可以是当前执行的代码块如定时任务、也可来自浏览器内核的其他线程如鼠标点击、AJAX异步请求等,但由于JS的单线程关系所有这些事件都得排队等待JS引擎处理。
异步http请求线程
在XMLHttpRequest在连接后是通过浏览器新开一个线程请求, 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件放到 JavaScript引擎的处理队列中等待处理。
Javascript引擎线程
Javascript引擎,也可以称为JS内核,主要负责处理Javascript脚本程序,例如V8引擎。Javascript引擎线程理所当然是负责解析Javascript脚本,运行代码。 由于
JavaScript是可操纵DOM的,如果在修改这些元素属性同时渲染界面(即JavaScript线程和UI线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。因此为了防止渲染出现不可预期的结果,浏览器设置GUI渲染线程与JavaScript引擎为互斥的关系,当JavaScript引擎执行时GUI线程会被挂起,GUI更新会被保存在一个队列中等到引擎线程空闲时立即被执行。
喜欢这篇文章吗?
加载中...
评论
0 条登录后即可参与评论讨论
加载评论中...
相关文章
目录